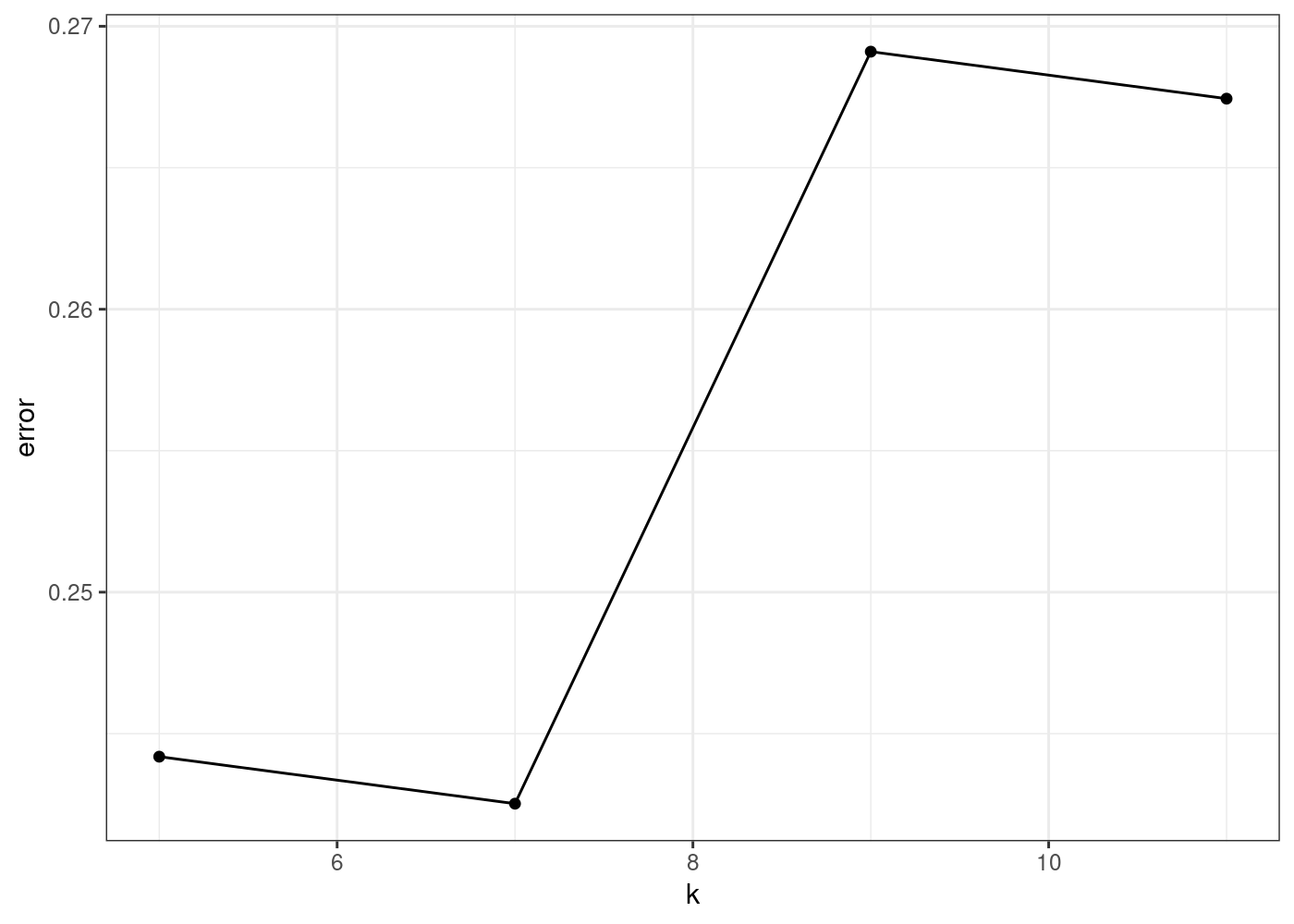
The value of \(k\) in the KNN algorithm is related to the error rate of the model. A small value of \(k\) could lead to overfitting, while a big value of \(k\) can lead to underfitting.
For binary data we want to avoid the case of ties. For example, if \(k = 2\), then we could have a case when one neighbor is \(Y = 0\) and the other one is \(Y = 1\).
Since we want to avoid overfitting - we will start from \(k = 5\).
misclasserror%>%ggplot(aes(x =k, y =error))+geom_line()+geom_point()+theme_bw()
1
1
Important
We have to be very carefull and include only explanatory variables, avoiding varibales like hours, wage, nwifeinc, etc., which have specific values as a consequence of being in the labor force.
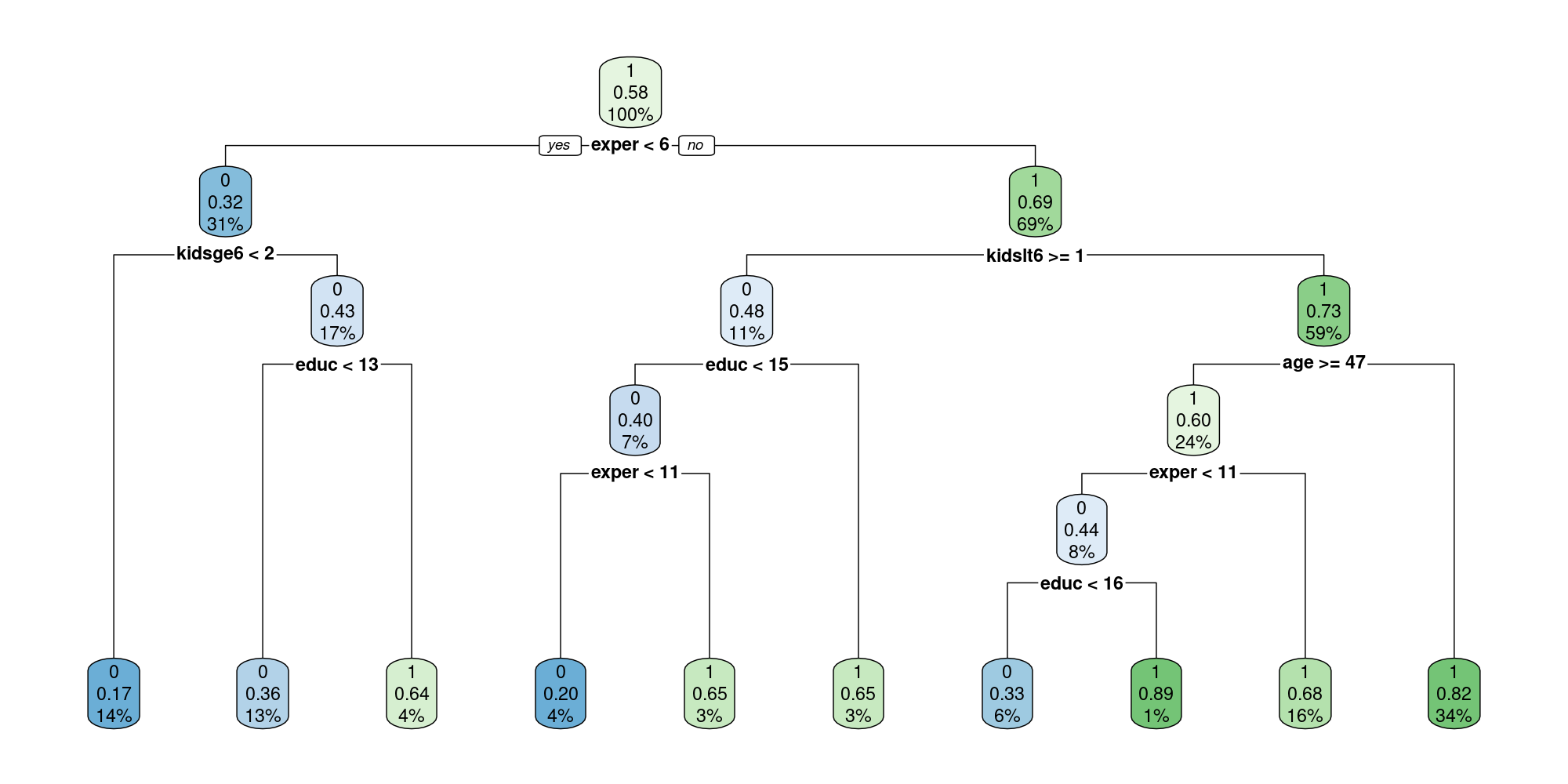
The predicted class (in our case - either 0 or 1).
The predicted probability
The percentage of observations in the node.
For example, at the first depth level - we see that if someone has less than 6 years of experience, then around \(31\%\) of (all) observations didn’t return to the labor force (the predicted probability is \(0.32\)), while \(69\%\) did return. Then, when we go one level down, we see that of those \(69\%\) who did return to the labor force, if they also had more than 1 child under 6 years old (kidslt6>=1), there is a probability of \(0.48\) that they won’t return to the labor force - around \(11\%\) of the total sample.
mdl_lda<-MASS::lda(factor(inlf)~educ+exper+age+kidslt6+kidsge6, data =dt_train)mdl_qda<-MASS::qda(factor(inlf)~educ+exper+age+kidslt6+kidsge6, data =dt_train)mdl_nbc<-e1071::naiveBayes(factor(inlf)~educ+exper+age+kidslt6+kidsge6, data =dt_train)