\(
\def\<#1>{\left<#1\right>}
\let\geq\geqslant
\let\leq\leqslant
% an undirected version of \rightarrow:
\newcommand{\mathdash}{\relbar\mkern-9mu\relbar}
\def\deg#1{\mathrm{deg}(#1)}
\newcommand{\dg}[1]{d_{#1}}
\newcommand{\Norm}{\mathrm{N}}
\newcommand{\const}[1]{c_{#1}}
\newcommand{\cconst}[1]{\alpha_{#1}}
\newcommand{\Exp}[1]{E_{#1}}
\newcommand*{\ppr}{\mathbin{\ensuremath{\otimes}}}
\newcommand*{\su}{\mathbin{\ensuremath{\oplus}}}
\newcommand{\nulis}{\vmathbb{0}} %{\mathbf{0}}
\newcommand{\vienas}{\vmathbb{1}}
\newcommand{\Up}[1]{#1^{\uparrow}} %{#1^{\vartriangle}}
\newcommand{\Down}[1]{#1^{\downarrow}} %{#1^{\triangledown}}
\newcommand{\lant}[1]{#1_{\mathrm{la}}} % lower antichain
\newcommand{\uant}[1]{#1_{\mathrm{ua}}} % upper antichain
\newcommand{\skal}[1]{\langle #1\rangle}
\newcommand{\NN}{\mathbb{N}} % natural numbers
\newcommand{\RR}{\mathbb{R}}
\newcommand{\minTrop}{\mathbb{T}_{\mbox{\rm\footnotesize min}}}
\newcommand{\maxTrop}{\mathbb{T}_{\mbox{\rm\footnotesize max}}}
\newcommand{\FF}{\mathbb{F}}
\newcommand{\pRR}{\mathbb{R}_{\mbox{\tiny $+$}}}
\newcommand{\QQ}{\mathbb{Q}}
\newcommand{\ZZ}{\mathbb{Z}}
\newcommand{\gf}[1]{GF(#1)}
\newcommand{\conv}[1]{\mathrm{Conv}(#1)}
\newcommand{\vvec}[2]{\vec{#1}_{#2}}
\newcommand{\f}{{\mathcal F}}
\newcommand{\h}{{\mathcal H}}
\newcommand{\A}{{\mathcal A}}
\newcommand{\B}{{\mathcal B}}
\newcommand{\C}{{\mathcal C}}
\newcommand{\R}{{\mathcal R}}
\newcommand{\MPS}[1]{f_{#1}} % matrix multiplication
\newcommand{\ddeg}[2]{\#_{#2}(#1)}
\newcommand{\length}[1]{|#1|}
\DeclareMathOperator{\support}{sup}
\newcommand{\supp}[1]{\support(#1)}
\DeclareMathOperator{\Support}{sup}
\newcommand{\spp}{\Support}
\newcommand{\Supp}[1]{\mathrm{Sup}(#1)} %{\mathcal{S}_{#1}}
\newcommand{\lenv}[1]{\lfloor #1\rfloor}
\newcommand{\henv}[1]{\lceil#1\rceil}
\newcommand{\homm}[2]{{#1}^{\langle #2\rangle}}
\let\daug\odot
\let\suma\oplus
\newcommand{\compl}[1]{Y_{#1}}
\newcommand{\pr}[1]{X_{#1}}
\newcommand{\xcompl}[1]{Y'_{#1}}
\newcommand{\xpr}[1]{X'_{#1}}
\newcommand{\cont}[1]{A_{#1}} % content
\def\fontas#1{\mathsf{#1}} %{\mathrm{#1}} %{\mathtt{#1}} %
\newcommand{\arithm}[1]{\fontas{Arith}(#1)}
\newcommand{\Bool}[1]{\fontas{Bool}(#1)}
\newcommand{\linBool}[1]{\fontas{Bool}_{\mathrm{lin}}(#1)}
\newcommand{\rBool}[2]{\fontas{Bool}_{#2}(#1)}
\newcommand{\BBool}[2]{\fontas{Bool}_{#2}(#1)}
\newcommand{\MMin}[1]{\fontas{Min}(#1)}
\newcommand{\MMax}[1]{\fontas{Max}(#1)}
\newcommand{\negMin}[1]{\fontas{Min}^{-}(#1)}
\newcommand{\negMax}[1]{\fontas{Max}^{-}(#1)}
\newcommand{\Min}[2]{\fontas{Min}_{#2}(#1)}
\newcommand{\Max}[2]{\fontas{Max}_{#2}(#1)}
\newcommand{\convUn}[1]{\fontas{L}_{\ast}(#1)}
\newcommand{\Un}[1]{\fontas{L}(#1)}
\newcommand{\kUn}[2]{\fontas{L}_{#2}(#1)}
\newcommand{\Nor}{\mu} % norm without argument
\newcommand{\nor}[1]{\Nor(#1)}
\newcommand{\bool}[1]{\hat{#1}} % Boolean version of f
\newcommand{\bphi}{\phi} % boolean circuit
\newcommand{\xf}{\boldsymbol{\mathcal{F}}}
\newcommand{\euler}{\mathrm{e}}
\newcommand{\ee}{f} % other element
\newcommand{\exchange}[3]{{#1}-{#2}+{#3}}
\newcommand{\dist}[2]{{#2}[#1]}
\newcommand{\Dist}[1]{\mathrm{dist}(#1)}
\newcommand{\mdist}[2]{\dist{#1}{#2}} % min-max dist.
\newcommand{\matching}{\mathcal{M}}
\renewcommand{\E}{A}
\newcommand{\F}{\mathcal{F}}
\newcommand{\set}{W}
\newcommand{\Deg}[1]{\mathrm{deg}(#1)}
\newcommand{\mtree}{MST}
\newcommand{\stree}{{\cal T}}
\newcommand{\dstree}{\vec{\cal T}}
\newcommand{\Rich}{U_0}
\newcommand{\Prob}[1]{\ensuremath{\mathrm{Pr}\left\{{#1}\right\}}}
\newcommand{\xI}{\boldsymbol{I}}
\newcommand{\plus}{\mbox{\tiny $+$}}
\newcommand{\sgn}[1]{\left[#1\right]}
\newcommand{\ccompl}[1]{{#1}^*}
\newcommand{\contr}[1]{[#1]}
\newcommand{\harm}[2]{{#1}\,\#\,{#2}} %{{#1}\,\oplus\,{#2}}
\newcommand{\hharm}{\#} %{\oplus}
\newcommand{\rec}[1]{1/#1}
\newcommand{\rrec}[1]{{#1}^{-1}}
\DeclareRobustCommand{\bigO}{%
\text{\usefont{OMS}{cmsy}{m}{n}O}}
\newcommand{\dalyba}{/}%{\oslash}
\newcommand{\mmax}{\mbox{\tiny $\max$}}
\newcommand{\thr}[2]{\mathrm{Th}^{#1}_{#2}}
\newcommand{\rectbound}{h}
\newcommand{\pol}[3]{\sum_{#1\in #2}{#3}_{#1}\prod_{i=1}^n x_i^{#1_i}}
\newcommand{\tpol}[2]{\min_{#1\in #2}\left\{\skal{#1,x}+\const{#1}\right\}}
\newcommand{\comp}{\circ} % composition
\newcommand{\0}{\vec{0}}
\newcommand{\drops}[1]{\tau(#1)}
\newcommand{\HY}[2]{F^{#2}_{#1}}
\newcommand{\hy}[1]{f_{#1}}
\newcommand{\hh}{h}
\newcommand{\hymin}[1]{f_{#1}^{\mathrm{min}}}
\newcommand{\hymax}[1]{f_{#1}^{\mathrm{max}}}
\newcommand{\ebound}[2]{\partial_{#2}(#1)}
\newcommand{\Lpure}{L_{\mathrm{pure}}}
\newcommand{\Vpure}{V_{\mathrm{pure}}}
\newcommand{\Lred}{L_1} %L_{\mathrm{red}}}
\newcommand{\Lblue}{L_0} %{L_{\mathrm{blue}}}
\newcommand{\epr}[1]{z_{#1}}
\newcommand{\wCut}[1]{w(#1)}
\newcommand{\cut}[2]{w_{#2}(#1)}
\newcommand{\Length}[1]{l(#1)}
\newcommand{\Sup}[1]{\mathrm{Sup}(#1)}
\newcommand{\ddist}[1]{d_{#1}}
\newcommand{\sym}[2]{S_{#1,#2}}
\newcommand{\minsum}[2]{\mathrm{MinS}^{#1}_{#2}}
\newcommand{\maxsum}[2]{\mathrm{MaxS}^{#1}_{#2}} % top k-of-n function
\newcommand{\cirsel}[2]{\Phi^{#1}_{#2}} % its circuit
\newcommand{\sel}[2]{\sym{#1}{#2}} % symmetric pol.
\newcommand{\cf}[1]{{#1}^{o}}
\newcommand{\Item}[1]{\item[\mbox{\rm (#1)}]} % item in roman
\newcommand{\bbar}[1]{\underline{#1}}
\newcommand{\Narrow}[1]{\mathrm{Narrow}(#1)}
\newcommand{\Wide}[1]{\mathrm{Wide}(#1)}
\newcommand{\eepsil}{\varepsilon}
\newcommand{\amir}{\varphi}
\newcommand{\mon}[1]{\mathrm{mon}(#1)}
\newcommand{\mmon}{\alpha}
\newcommand{\gmon}{\alpha}
\newcommand{\hmon}{\beta}
\newcommand{\nnor}[1]{\|#1\|}
\newcommand{\inorm}[1]{\left\|#1\right\|_{\mbox{\tiny $\infty$}}}
\newcommand{\mstbound}{\gamma}
\newcommand{\coset}[1]{\textup{co-}{#1}}
\newcommand{\spol}[1]{\mathrm{ST}_{#1}}
\newcommand{\cayley}[1]{\mathrm{C}_{#1}}
\newcommand{\SQUARE}[1]{\mathrm{SQ}_{#1}}
\newcommand{\STCONN}[1]{\mathrm{STCON}_{#1}}
\newcommand{\STPATH}[1]{\mathrm{PATH}_{#1}}
\newcommand{\SSSP}[1]{\mathrm{SSSP}(#1)}
\newcommand{\APSP}[1]{\mathrm{APSP}(#1)}
\newcommand{\MP}[1]{\mathrm{MP}_{#1}}
\newcommand{\CONN}[1]{\mathrm{CONN}_{#1}}
\newcommand{\PERM}[1]{\mathrm{PER}_{#1}}
\newcommand{\mst}[2]{\tau_{#1}(#2)}
\newcommand{\MST}[1]{\mathrm{MST}_{#1}}
\newcommand{\MIS}{\mathrm{MIS}}
\newcommand{\dtree}{\mathrm{DST}}
\newcommand{\DST}[1]{\dtree_{#1}}
\newcommand{\CLIQUE}[2]{\mathrm{CL}_{#1,#2}}
\newcommand{\ISOL}[1]{\mathrm{ISOL}_{#1}}
\newcommand{\POL}[1]{\mathrm{POL}_{#1}}
\newcommand{\ST}[1]{\ptree_{#1}}
\newcommand{\Per}[1]{\mathrm{per}_{#1}}
\newcommand{\PM}{\mathrm{PM}}
\newcommand{\error}{\epsilon}
\newcommand{\PI}[1]{A_{#1}}
\newcommand{\Low}[1]{A_{#1}}
\newcommand{\node}[1]{v_{#1}}
\newcommand{\BF}[2]{W_{#2}[#1]} % Bellman-Ford
\newcommand{\FW}[3]{W_{#1}[#2,#3]} % Floyd-Washall
\newcommand{\HK}[1]{W[#1]} % Held-Karp
\newcommand{\WW}[1]{W[#1]}
\newcommand{\pWW}[1]{W^{+}[#1]}
\newcommand{\nWW}[1]{W^-[#1]}
\newcommand{\knap}[2]{W_{#2}[#1]}
\newcommand{\Cut}[1]{w(#1)}
\newcommand{\size}[1]{\mathrm{size}(#1)}
\newcommand{\dual}[1]{{#1}^{\ast}}
\def\gcd#1{\mathrm{gcd}(#1)}
\newcommand{\econt}[1]{C_{#1}}
\newcommand{\xecont}[1]{C_{#1}'}
\newcommand{\rUn}[1]{\fontas{L}_{r}(#1)}
\newcommand{\copath}{\mathrm{co}\text{-}\mathrm{Path}_n}
\newcommand{\Path}{\mathrm{Path}_n}
\newcommand{\slice}[2]{Q^{#1}_{#2}}
\)
Matroids, greedy algorithm and approximating tropical circuits
Contents
1. Matroids
A set $A\subseteq\{0,1\}^n$ is a matroid (or, more precisely, a set of bases of a matroid) if $A$ is homogeneous (all vectors have the same number of $1$s, usually called the rank of the matroid) and the
basis exchange axiom holds:
- if $a\neq b\in A$, then for
every position $i\in\supp{a}\setminus\supp{b}$ (that is, $a_i=1$ and $b_i=0$) there is a position $j\in\supp{b}\setminus\supp{a}$
(that is, $a_i=0$ and $b_i=1$)
such that the vector $a-\vec{e}_i+\vec{e}_j$ belongs to $A$.
The vector $a-\vec{e}_i+\vec{e}_j$
is obtained from $a$ by switching the $i$th position from $1$ to $0$ and
switching the $j$th position from $0$ to $1$:
\[
\begin{array}{rcccccc}
& & & i & & j & \\
a & = & \cdots & 1 & \cdots\cdots & 0 & \cdots \\
a-\vec{e}_i+\vec{e}_j & = & \cdots & 0 & \cdots\cdots & 1 & \cdots
\end{array}
\]
By a classical result of Rado [2],
both the maximization
and the minimization problems on matroids $A$ can be solved (exactly, within approximation factor $r=1$) by the greedy algorithm
which we recall in the Appendix below.
The following simple proposition gives us a lot of matroids.
Let $\slice{n}{m}\subseteq \{0,1\}^n$ be the set of all $|\slice{n}{m}|=\binom{n}{m}$
vectors $a\in \{0,1\}^n$ with $a_1+\cdots+a_n=m$ ones.
A set $B\subseteq \{0,1\}^n$ is a Hamming set if every two distinct its vectors differ in more than two positions. Lemma 4.12 in the book shows
that there are at least $2^{\binom{n}{m}/n}$ Hamming sets $B\subseteq \slice{n}{m}$. In Remark 4.14 of the book, the following fact was shown (in terms of families of sets instead of sets of their characteristic $0$-$1$ vectors).
Proposition: Let $3\leq m\leq n-2$.
For every Hamming set $B\subseteq \slice{n}{m}$, the set $A=\slice{n}{m}\setminus B$ is a matroid.
Proof:
For the sake of contradiction, suppose that $A$ is not a matroid.
Then, since the set $A$ is homogeneous, there must be two
vectors $a\neq b\in A$
violating the basis exchange axiom: there
is a position $i\in\supp{a}\setminus\supp{b}$
such that for every position $j\in\supp{b}\setminus\supp{a}$ the vector
$a-\vec{e}_i+\vec{e}_j$ does not belong to $A$; hence, each of these
vectors $a-\vec{e}_i+\vec{e}_j$ belong to the set $B$.
Observe that the set $\supp{b}\setminus \supp{a}$ must have at least two positions: if $\supp{b}\setminus \supp{a}-\{j\}$ held
then, since both vectors $a$ and $b$ have the same number of $1$s,
the vector $a-\vec{e}_i+\vec{e}_j$ would
coincide with the vector $b$ and, hence, would belong to $A$.
So, take any two positions $j\neq l\in \supp{b}\setminus \supp{a}$,
and consider the vectors $c=a-\vec{e}_i+\vec{e}_j$ and
$d=a-\vec{e}_i+\vec{e}_l$.
Since the basis exchange axiom
fails for the set $A$, neither $c$ nor $d$ can belong to $A$;
hence, both vectors $c$ and $d$ belong to the
set $B\setminus\slice{n}{m}$. But these two vectors differ in only two positions ($j$ and $k$),
a contradiction with $B$ being a Hamming set.
∎
That tropical circuits can considerably outperform the greedy algorithm
is long known. For example, there are explicit sets $A\subseteq\{0,1\}^n$ of
feasible solutions such that both maximization and minimization problems on $A$ can be exactly solved by $(\max,+)$ and $(\min,+)$ circuits
of small size, but the greedy algorithm cannot even approximate any of these two problems within any factor $r\lt n-1$
(see Fact 2 in the Appendix).
Hence, a natural question arises: can also greedy substantially outperform
tropical circuits? The following Fact 1 shows: yes, sometimes it can.
2. Known gaps
For a set $A\subseteq\{0,1\}^n$, let (as in the book) $\Bool{A}$ be the minimum size of a monotone Boolean $(\lor,\land)$ circuit computing the monotone Boolean function $f_A(x):=\bigvee_{a\in A}\bigwedge_{i : a_i=1}x_i$. That is, $f_A(x)=1$ iff $x\geq a$ for some
$a\in A$.
Also, $\Min{A}{r}$ and $\Max{A}{r}$
denote, respectively, the minimum size of a $(\min,+)$ and of a $(\max,+)$ circuit approximating the minimization problem $f(x)=\min_{a\in A}\skal{a,x}$ or maximization problem
$f(x)=\max_{a\in A}\skal{a,x}$.
on a given set $A\subseteq \NN^n$ of feasible solution with the factor $r$.
Recall that a tropical circuit $\Phi$ approximates a given optimization
problem $f:\RR_+^n\to\RR_+$ within a factor $r\geq 1$ if for every input weighting
$x\in\RR_+^n$, the output value $\Phi(x)$ of the circuit lies:
- between $f(x)$ and $r\cdot f(x)$, in the case when $f$
is a minimization problem;
- between $f(x)/r$ and $f(x)$, in the case when $f$ is a
maximization problem.
Thus, $\Min{A}{r}\geq t$ means that for every $(\min,+)$ circuit
$\Phi$ of size $\lt t$ there is an input weighting $x\in\RR_+^n$ such that either
$\Phi(x) \lt f(x)$ (the circuit wrongly outputs better than optimal value) or $\Phi(x) \gt r\cdot f(x)$
(the value computed by the circuit is larger than $r$ times the optimal value).
We have the following fact (as a direct consequence of Corollary 4.13
and Remark 4.12 in the book).
Fact 1: There is a family $\A\subseteq 2^{n]}$ of $|\A|=2^{2^{\Omega(n)}}$ matroids $A\subseteq\{0,1\}^n$
such that the following holds for
each $A\in\A$.
- $\Min{A}{r}\geq \Bool{A}=2^{\Omega(n)}$ for any finite approximation factor $r\geq 1$;
- $\Max{A}{r}=2^{\Omega(n)}$ for $r=1$;
- $\Max{A}{r}=O(n^2)$ for $r=1+o(1)$.
Moreover, the maximization problem on all these matroids $A$ can be
approximated with a factor $r=1+o(1)$ by one single $(\max,+)$ circuit of size $O(n^2)$.
Remark 1:
The small $(\max,+)$ circuit in Fact 1 approximating the maximization problem on all these matroids $A$ with a factor $r=1+o(1)$
solves exactly the following
maximization problem
\[
\sym{n}{k}(x_1,\ldots,x_n)=\max\Big\{\sum_{i\in S}x_i\colon
S\subseteq [n], |S|=k\Big\}\,.
\]
That is, $\sym{n}{k}$ outputs the sum of $k$ largest numbers from among $x_1,\ldots,x_n$.
The pure DP algorithm for the problem $\sym{n}{k}$ takes
$\sym{m}{1}(x)=\max\{x_1, x_2, \ldots, x_m\}$ and
$\sym{r}{r}(x)=x_1+ \cdots +x_r$ as initial values are.
recursion equation is
\[
\sym{m}{r}(x_1,\ldots,x_{m})
=\max\left\{\sym{m-1}{r}(x_1,\ldots,x_{m-1}),\
\sym{m-1}{r-1}(x_1,\ldots,x_{m-1})+x_m\right\}\,.
\]
The recursion is based on the following simple observation: every $r$-element subset $S\subseteq [m]$ is either an
$r$-element subset of $[m-1]$ (if $m\not\in S$), or is of the form
$S=T\cup\{m\}$ for some $(r-1)$-element subset
$T\subseteq[m-1]$.
$\Box$
Fact 1 raises several problems.
3. Matroids and $(\lor,\land)$ circuits
By Fact 1, there exist a lot of matroids $A$ such that the corresponding Boolean functions $f_A$ require monotone Boolean $(\lor,\land)$ circuits of exponential size.
But we do not know any explicit matroid for which this holds.
Problem 1: Exhibit an explicit matroid $A\subseteq\{0,1\}^n$ for which $\Bool{A}$ is super-polynomial.
4. Matroids and approximating (max,+) circuits
By Fact 1, the minimization
problem on a huge number matroids $A\subseteq\{0,1\}^n$ cannot be efficiently approximated by $(\min,+)$ circuits within any finite factor $r\geq 1$. Fact 1 also shows that the maximization problem on all these matroids $A$ can be approximated within a factor $r=1+o(1)$ by one single $(\max,+)$ circuit of size $O(n^2)$. Are there matroids $A$ at all, the maximization problem on which cannot be
efficiently approximated by tropical $(\max,+)$ circuits within some slightly large factor $r$?
Problem 2: Are there matroids $A\subseteq\{0,1\}^n$
for which $\Max{A}{r}=\Omega(n^3)$ holds for some factor
$r = 1+\epsilon$ with a constant $\epsilon >0$?
Note that we only ask for the mere existence. By counting arguments, the answer is YES for $r=1$. But Fact 1 indicates that counting
arguments may fail to answer this question for slightly larger
approximation factors $r=1+\epsilon>1$.
5. Spanning trees
Let $\spol{n}\subseteq\{0,1\}^{\binom{n}{2}}$ be the set of characteristic $0$-$1$ vectors of all $|\spol{n}|=n^{n-2}$ spanning trees of $K_n$ (the trees are viewed as sets of their edges). It is well known that $\spol{n}$ is a matroid (in fact, this is a basic example of a matroid in the literature). So, both minimization and maximization problems on $\spol{n}$ can be solved by a greedy algorithm.
On the other hand, we know (Theorem 3.16 in the book) that both $\Min{\spol{n}}{r}=2^{\Omega(\sqrt{n})}$ and
$\Max{\spol{n}}{r}=2^{\Omega(\sqrt{n})}$ hold for the approximation factor $r=1$ (exactly solving tropical circuits).
Problem 3: Is $\Min{\spol{n}}{2}$ and/or $\Max{\spol{n}}{2}$ polynomial in $n$?
By Theorem 6.5 in the book, we know that the minimization problem on $\spol{n}$ can be solved by a $(\min,+)$ circuit of size $O(n^3)$ even exactly (within factor $r=1$) as long as also $\max$ gates are allowed to be used. Problem 4 asks whether
without $\max$ gates $(\min,+)$ circuits can efficiently approximate the minimization problem on $\spol{n}$ at least within factor $2$.
6. Perfect matchings
Now consider the set $\PM_n\subseteq\{0,1\}^{n\times n}$
of characteristic $0$-$1$ vectors of all $|\PM_n|=n!$ perfect matchings in $K_{n,n}$. The maximization problem on $A$ can be
approximated by the greedy algorithm within factor $r=2$:
just always pick the heaviest of the remaining edges, untouched by
the partial matching picked so far.
On the other hand, we know (Theorem 3.6 in the book) that
$\Max{\PM_n}{r}=2^{\Omega(n)}$ holds for the approximation factor $r=1$ (exactly solving tropical circuits).
Problem 4: Is $\Max{\PM_n}{2}$ polynomial in $n$?
A more general problem is to compute the maximum weight of a perfect matching in
$k$-partite $k$-uniform hypergraphs. In this comment, it is shown that
for every constant $k\geq 6$, every
$(\max,+)$ circuit approximating this problem within the factor
$r=2^k/9$ must have exponential size. However, this argument
fails (purely numerically) for smaller than $6$ values of $k$ and, in particular, for $k=2$ (as in Problem 4). It is not clear whether some modification of this argument can also work also in case $k=2$.
Appendix: greedy algorithms
Depending on whether we want to solve the maximization of the maximization
problem on a given antichain $A\subseteq\{0,1\}^n$ of feasible solutions, the greedy algorithm works as follows. When an input weighting $\in\RR_+^n$ arrives, both maximizing and minimizing greedy algorithms
use the same heaviest-first ordering $x_1\geq x_2\geq\ldots\geq x_n$ (by before reordering, if necessary, the ground elements $[n]=\{1,\ldots,n\}$ using any sorting algorithm).
Then both algorithms treat the elements $i=1,2,\cdots,n$ one-by-one.
- Maximization (best-in strategy): Start with the all-$0$ vector $b:=\vec{0}$ and iteratively do the following, where $b\in\{0,1\}^n$ is the vector obtained from $\vec{0}$ after $i-1$ steps.
- At the $i$th step, set $b:=b+\vec{e}_i$ iff vector $b+\vec{e}_i$ is contained in at least
one feasible solution, that is, iff $b+\vec{e}_i\leq a$ holds for at least one vector $a\in A$.
In this case, we say that the position $i$ was accepted.
- After all $n$ positions are treated, the algorithm outputs
$\skal{b,x}=b_1x_1+\cdots+b_nx_n$.
- Minimization (worst-out strategy): Start with the all-$1$ vector $b:=\vec{1}$ and iteratively do the following, where $b\in\{0,1\}^n$ is the vector obtained from $\vec{1}$ after $i-1$ steps.
- At the $i$th step, set $b:=b-\vec{e}_i$ iff vector $b-\vec{e}_i$ contains at least one feasible
solution, that is, iff $b-\vec{e}_i\geq a$ holds for at least one vector $a\in A$.
In this case, we say that the position $i$ was rejected.
- After all $n$ positions are treated, the algorithm outputs
$\skal{b,x}=b_1x_1+\cdots+b_nx_n$.
In both cases, the obtained vector $b$ belongs to $A$. Indeed, the final vector $b$ obtained by the maximizing greedy starting from vector $b=\vec{0}$ cannot have a position $i$ such that $b_i=0$ while $a_i=1$ for all $a\in A$, because then this entry would have been switched to $b_i=1$ at the $i$th step of the algorithm. Similarly for the minimizing greedy algorithm.
Remark 2:
The choice of these special strategies (first-in for maximization
and first-out for minimization) is not an accident. Namely, the greedy
algorithm starting with the lightest-first ordering $x_1\leq
x_2\leq \ldots\leq x_n$, and using the worst-out strategy for maximization or best-in strategy
for minimization would be unable to
approximate some optimization problems within any finite factor.
To
give a simple example, consider the path with three nodes
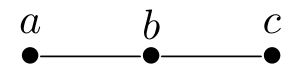
and let $A\subseteq \{0,1\}^3$ consist of the two characteristic
$0$-$1$ vectors of the two maximal independent sets $\{a,c\}$ and $\{b\}$
of this path.
If we take an arbitrarily large number $M>1$, and give
weights $x_a=0$, $x_b=1$ and $x_c=M$, then both these greedy algorithms will treat the vertices in the order $a,b,c$. The worst-out maximizing greedy on $A$ would output $x_b=1$ while the optimum is $M$, and the best-in greedy for
minimization would output $x_a+x_c=0+M$, while the optimum is $1$. In both
cases, the achieved approximation factor is $r\geq M$ (arbitrarily large).
$\Box$
The following simple fact shows that on some sets $A\subseteq\{0,1\}^n$ of feasible solutions, the greedy algorithm can fail to achieve small approximation factors even when using "right" strategies
(best-in for maximization and worst-out for minimization).
Say that a set $A\subseteq\{0,1\}^n$ is
$m$-bounded if no its vector has more than $m$ $1$s.
Fact 2:
For any integer $1\leq m\lt n$, the greedy algorithm approximates the optimization (maximization and minimization) problem on every $m$-bounded set $A\subseteq\{0,1\}^n$ within the factor $r_A\leq m$, and
there are (explicit) $m$-bounded antichains $A\subseteq\{0,1\}^n$ such that $r_A\geq m$ whereas
$\Max{A}{r}\leq m$ and $\Min{A}{r}\leq m$ hold for the factor $r=1$.
Proof:
To show the upper bound $r_A\leq m$ for every $m$-bounded set $A\subseteq\{0,1\}^n$, take an arbitrary weighting
$x_1,x_2,\ldots,x_n\in\RR_+$ of ground elements $[n]=\{1,\ldots,n\}$. Suppose w.l.o.g. that $x_1\geq x_2\geq\ldots\geq x_n$; if not, then reorder the indices to get the desired heaviest-first ordering (recall that both maximizing and minimizing greedy algorithms start with the heaviest-first ordering). Let $i\in [n]$ be the
first element accepted (resp, rejected in the case of minimization) by the greedy algorithm.
Let $a\in A$ be an optimal solution for the input $x$ (that is, $f(x)=\skal{a,x}$), and $b\in A$ be the
solution found by the greedy algorithm. Let also $S:=\{i\colon a_i=1\}$ and $T:=\{i\colon b_i=1\}$. Since $a,b\in A$ and the set $A$ is $m$-bounded, we have $|S|,|T|\leq m$.
The set $S\subseteq [n]$ can be thought of as an optimal set of ground elements, and $T\subseteq [n]$ as the set found by the greedy algorithm.
Case 1: We deal with the maximizing (best-in) greedy algorithm.
Let $i\in [n]$ be the
first accepted element. Then $i$ is the first
element belonging to at least one feasible set. So, $T\cap
\{1,\ldots,i-1\}=\emptyset$, implying that $\skal{b,x}\leq |T|\cdot
x_i\leq m\cdot x_i\leq m\cdot \skal{a,x}$, as desired.
Case 2:
We deal with the minimizing (worst-out) greedy algorithm.
Let $i\in [n]$ be the
first not rejected element.
Then the set
$\{i+1,\ldots,n\}$ cannot contain any feasible solution (for
otherwise, $i$ would not be rejected). But then
$\skal{b,x}\geq x_{i-1}\geq x_i$, whereas $\skal{a,x}\leq |S|\cdot x_i\leq
m\cdot x_i$, implying that $\skal{b,x}\leq m\cdot \skal{a,x}$, as desired.
To show that $r_A\geq m$ holds for some $m$-bounded antichain $A\subseteq\{0,1\}^n$, it is enough to show that $r_A > (1-\epsilon)m$ holds for arbitrarily small number $\epsilon \gt 0$. Consider the $m$-bounded antichain $A=\{\vec{e}_1, \vec{e}_2+\cdots+\vec{e}_{m+1}\}$ consisting of just two vectors. Give weight $x_1:=1/(1-\epsilon)\gt 1$ to the first element, weights $x_2=x_3=\ldots=x_n:=1$ to the next $m$ elements, and zero weight to the remaining $n-(m+1)$ ground elements $i\in[n]$.
The maximizing (best-in) greedy will
output $x_1$ while the optimum is $x_2+\cdots+x_{m+1}=m$, and the minimizing
(worst-out) greedy algorithms will output $x_2+\cdots+x_{m+1}=m$
while the optimum is
$x_1$. In both cases, the achieved approximation factor is
$r\geq m/x_1 \gt (1-2\epsilon)m$.
The upper bounds $\Max{A}{1}\leq m$ and $\Min{A}{1}\leq m$ for this particular set $A$ are trivial because the maximization and minimization
problems on $A$ are to compute the maximum or the minimum of $x_1$ and $x_2+\cdots+x_{m+1}$.
$\Box$
Remark 3:
By Fact 2, the greedy algorithm (using "right" strategies, the best-in for maximization and worst-out for minimization) can approximate both optimization problems on any set $A\subseteq\{0,1\}^n$ within (a possibly large by bounded) factor $r\leq n$. The algorithm first sorts the input weights (this can be easily done), and then performs only $n$ steps.
Note, however, that unlike the best-in strategy used for maximization.
the worst-out strategy used for minimization can be rather difficult to implement efficiently. The point is that this strategy may be forced to solve (at each step) hard
(even NP-hard) decision problems: does the remaining set of ground
elements still contains at least one feasible solution? For
example, in the case of the lightest $k$-clique problem for $k=n/2$, the
oracle must be able to solve, in each step, an NP-complete problem: does the
current graph still contains a $k$-clique?
$\Box$
References:
- S. Jukna and H. Seiwert: Approximation limitations of pure dynamic programming, SIAM J. Comput., 49:1 (2020) 170-207.
arxiv
- R. Rado: A theorem on independence relations,
Quart. J. Math. 13 (1942) 83-89.
⇦ Back to the comments page